Web Search using Python and Google Search Engine 2022
In this tutorial we will crawl the web using Python to search for a certain keyword, and get back the results from google.
We need to install beautifulsoup and requests module because this will help us to search our content and get the content data from the web and show in the terminal.
- requests module is used to reqeust the URL content we are searching for.
- Beautifulsoup is used to parse that result we got from requests
Installing beautifulsoup
pip install bs4
Installing requests python module
pip install requests
Using beautifulsoup and requests
Let's request a search on google. We first need the google link that we will psas to our requests.
The google search link should look like this:
https://www.google.com/search?q={content}&ln=en
We will replace the {content} section with our own search keyword.
So if we want to search for Cats, the link should look like this:
https://www.google.com/search?q=Cats&ln=en
To print out the parsed content, we use the .text method
from bs4 import BeautifulSoup
import requests
content="cats"
response = requests.get(url=f'https://www.google.com/search?q={content}&ln=en')
soup = BeautifulSoup(response.text,'html.parser')
print(soup.text)
Observing the output we are printing, we can see how messy it is, Let's organize it.
Even the results are not accurate, because google blocks crawlers scripts. So how to solve this.
Fixing Google cralwling blockage and organizing the search results
Google now requires registering for a search engine account before we can crawl with python scripts and any other external script.
Navigate to Programmable Search Engine by google.
Choose a name of your choice for your search engine and also check the information like the following image:
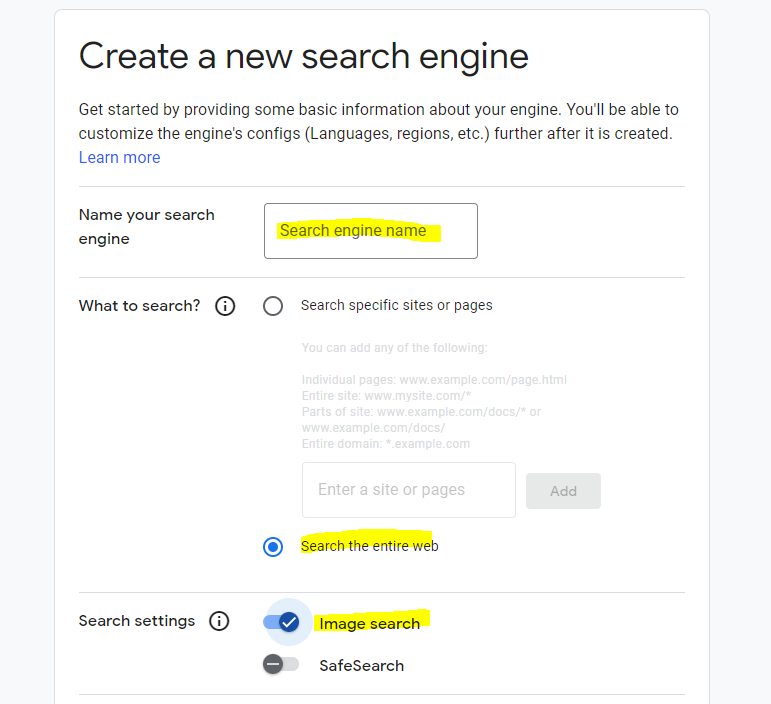
After you are done, click on go back to all engines, choose the engine you created and copy the Search Engine ID field.
Getting API Key
It is important that Google identify your python script.
So the final step is to get an API Key

Follow the steps, and copy the API Key
Searching the web using Google Search Engine
Now that our API Key and Search ID are ready, let us get some result!
import requests
API_KEY = 'YOUR_API'
SEAERCH_ID = 'YOUR_SEARCH_ID'
# the search query you want
query = "Cats"
# using the first page
start = 1
url = f"https://www.googleapis.com/customsearch/v1?key={API_KEY}&cx={SEAERCH_ID}&q={query}&start={start}"
data = requests.get(url).json()
We will use JSON method for parsing this time and we won't use Beautifulsoup.
url contains a place holder for both or search ID and API Key
Printing out the results
The data variable we had above contains multiple dictionary keys.
dict_keys(['kind', 'url', 'queries', 'context', 'searchInformation', 'items'])
You can have fun exploring them, for us now we are interested only in items
Items also has multiple keys:
dict_keys(['kind', 'title', 'htmlTitle', 'link', 'displayLink', 'snippet', 'htmlSnippet', 'cacheId', 'formattedUrl', 'htmlFormattedUrl', 'pagemap'])
We will use title, link, and snippet.
for item in data['items']:
print(item['title'])
print(item['link'])
print(item['snippet'])
print("========this is the result=========")
Full Python Google Search Engine Crawler code:
Let's test out the whole code
import requests
API_KEY = 'YOUR_API'
SEAERCH_ID = 'YOUR_ID'
# the search query you want
query = "Cats"
# using the first page
start = 1
url = f"https://www.googleapis.com/customsearch/v1?key={API_KEY}&cx={SEAERCH_ID}&q={query}&start={start}"
data = requests.get(url).json()
for item in data['items']:
print(item['title'])
print(item['link'])
print(item['snippet'])
print("========this is the result=========")
And the result is as expected! We are getting the page link, title and a snippet from the result text!
Cats | Healthy Pets, Healthy People | CDC https://www.cdc.gov/healthypets/pets/cats.html Nearly 40 million households in the United States have pet cats. Although cats are great companions, cat owners should be aware that sometimes cats can carry ... ========this is the result=========
Cats - Rotten Tomatoes https://www.rottentomatoes.com/m/cats_2019 A tribe of cats must decide yearly which one will ascend to the Heaviside Layer and come back to a new life. Rating: PG (Some Rude and Suggestive Humor). ========this is the result=========
CATS Academy Boston | Preparing you for university success https://www.catsacademyboston.com/ A co-educational day and boarding school Grades 9-12. ========this is the result=========